
Biweekly AWS Bytes: Week 4 - Unleashing Serverless Power with AWS Lambda
Welcome to Week 4 of KTM One's biweekly AWS blog series! After exploring foundational services like S3, RDS, and EC2, this week we're diving into one of AWS's most revolutionary offerings: AWS Lambda. If you've ever wondered how to build applications that scale automatically, run only when needed, and eliminate server management overhead, you're in for a treat.
What is AWS Lambda?
AWS Lambda is a serverless compute service that runs your code in response to events without requiring you to provision or manage servers. Think of it as having a team of invisible assistants who spring into action the moment something happens, whether it's a file upload, a database change, or a scheduled task, execute your code perfectly, then disappear until needed again.
The beauty of Lambda lies in its event-driven nature and automatic scaling. Your code runs in stateless compute containers that AWS manages completely, scaling from zero to thousands of concurrent executions in seconds. You pay only for the compute time you consume, measured in milliseconds, making it incredibly cost-effective for workloads with variable or unpredictable traffic patterns.
Lambda supports multiple programming languages including Python, Node.js, Java, C#, Go, and Ruby, allowing developers to work in their preferred environment while AWS handles all the underlying infrastructure complexity. This serverless approach has fundamentally changed how modern applications are built, enabling developers to focus purely on business logic rather than infrastructure management.
Key Highlights
- Event-Driven Architecture: Lambda functions automatically trigger in response to events from over 200 AWS services and SaaS applications, creating reactive systems that respond instantly to changes in your environment without polling or constant monitoring.
- Automatic Scaling: Handle anything from a few requests per day to thousands per second with zero configuration, as Lambda automatically scales your application by running code in parallel and processing each trigger individually.
- Pay-Per-Use Pricing: Pay only for the compute time your code actually consumes, with no charges for idle time, making it perfect for intermittent workloads and eliminating the need to provision and pay for unused capacity.
- Built-in High Availability: Run across multiple Availability Zones automatically with built-in fault tolerance, ensuring your functions remain available even if entire data centers experience issues.
- Seamless Integration: Connect effortlessly with the entire AWS ecosystem including S3, DynamoDB, API Gateway, EventBridge, and hundreds of other services through native triggers and destinations.
- Zero Server Management: Focus entirely on your code while AWS handles server provisioning, patching, scaling, and monitoring, dramatically reducing operational overhead and time-to-market for new features.
- Sub-Second Billing: Get charged in 1-millisecond increments after the first 100ms of execution time, ensuring you never pay for unused compute resources and making even the smallest workloads economically viable.
- Enterprise Security: Leverage AWS IAM for fine-grained access control, VPC integration for network isolation, and encryption at rest and in transit, meeting the most stringent security and compliance requirements.
Top Use Cases of AWS Lambda
File Processing Use Cases
PDF Encryption Application
Modern businesses handle countless sensitive documents daily, from financial reports and legal contracts to personal information and proprietary research. The challenge lies in ensuring these documents remain secure from the moment they're uploaded to your systems. Manual encryption processes are time-consuming, error-prone, and don't scale with business growth.
AWS Lambda transforms document security by providing instant, automated encryption that activates the moment sensitive files hit your systems. When a PDF document is uploaded to an S3 bucket, Lambda springs into action within milliseconds, applying enterprise-grade encryption before storing the secured document in a separate, highly protected bucket.
Common Problem Statements:
- How can we automatically encrypt sensitive documents without manual intervention or delays?
- What's the most efficient way to ensure all uploaded PDFs meet our security compliance requirements?
- How do we scale document encryption to handle thousands of files daily without infrastructure overhead?
- Can we implement document security that works seamlessly with our existing file upload workflows?
Solution Architecture:
Configure an S3 bucket with event notifications that trigger a Lambda function whenever a PDF file is uploaded. The Lambda function retrieves the document, applies AES-256 encryption using AWS KMS customer-managed keys, and stores the encrypted file in a secure S3 bucket with restricted access policies. Implement error handling to move problematic files to a quarantine bucket for manual review, and use CloudWatch for monitoring encryption success rates and processing times. This architecture can process thousands of documents simultaneously while maintaining audit trails for compliance reporting.
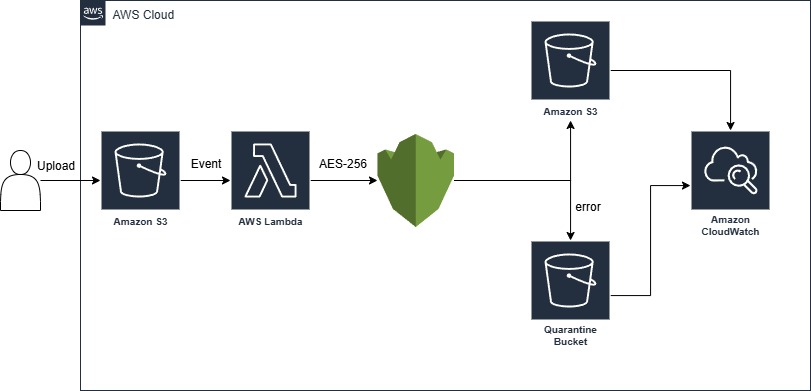
Image Analysis Application
In our visual-first digital world, organizations accumulate massive libraries of images containing valuable text and insights. From digitizing historical documents and processing insurance claims to moderating user-generated content and extracting data from screenshots, the manual review of images is becoming increasingly impractical.
Lambda combined with Amazon Rekognition creates powerful image analysis workflows that can extract text, identify objects, detect inappropriate content, and analyze sentiment in real-time. This automation transforms how businesses handle visual content, turning what was once a manual, time-intensive process into an instant, scalable operation.
Common Problem Statements:
- How can we automatically extract text from thousands of images without manual data entry?
- What's the best way to implement content moderation for user-uploaded images at scale?
- How do we process document images to make their content searchable and analyzable?
- Can we automatically categorize and tag images based on their visual content?
Solution Architecture:
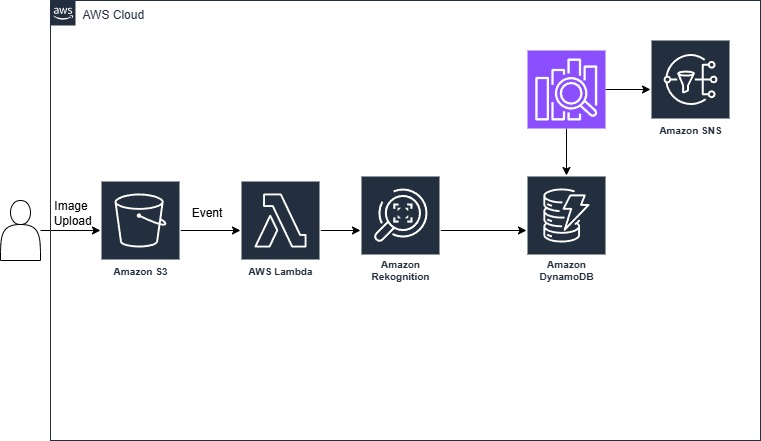
Set up S3 event notifications to trigger Lambda functions when images are uploaded. The Lambda function calls Amazon Rekognition APIs to extract text using OCR, detect objects and scenes, identify faces, or flag inappropriate content based on your requirements. Store extracted metadata in DynamoDB for fast querying, index text content in Amazon OpenSearch for full-text search capabilities, and use SNS to notify relevant teams when specific content types are detected. For high-volume scenarios, implement SQS queues to handle processing bursts and ensure no images are lost during peak upload periods.
Database Integration Scenarios
Queue-to-Database Application
Modern applications often need to handle bursts of user activity gracefully, from flash sales and viral content to system integrations and batch data imports. Direct database writes during these spikes can overwhelm your database, leading to timeouts, failed transactions, and poor user experiences. Traditional solutions require complex infrastructure and careful capacity planning.
Lambda provides an elegant solution by decoupling user actions from database writes through message queues. When users register for accounts, place orders, or submit forms, their requests are immediately acknowledged and queued for processing. Lambda functions then process these queues at optimal rates, ensuring your database remains responsive while guaranteeing that no user data is lost.
Common Problem Statements:
- How can we handle sudden spikes in user registrations without overwhelming our database?
- What's the most reliable way to process order submissions during high-traffic periods?
- How do we ensure data consistency when processing thousands of concurrent user actions?
- Can we decouple user-facing operations from backend processing for better performance?
Solution Architecture:
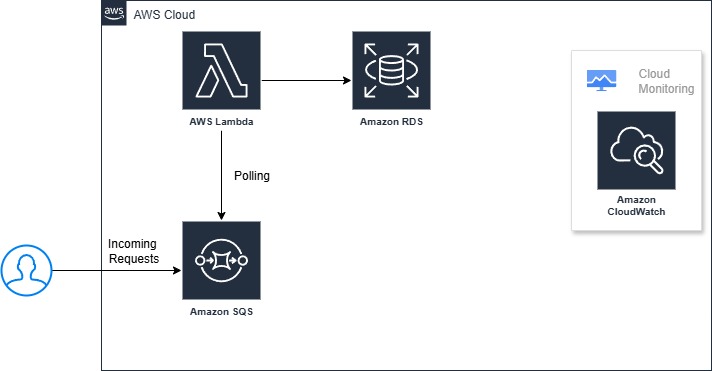
Use Amazon SQS to queue incoming user requests, with Lambda functions polling the queue for new messages. Configure the Lambda function to batch process multiple messages simultaneously, writing them to Amazon RDS using connection pooling to optimize database performance. Implement dead letter queues for failed processing attempts, use CloudWatch metrics to monitor queue depth and processing rates, and set up Auto Scaling for Lambda concurrency based on queue length. For high-volume scenarios, consider using SQS FIFO queues for ordered processing or multiple standard queues for parallel processing of different data types.
Database Event Handler
In distributed systems, changes to one piece of data often need to trigger updates elsewhere, updating search indexes, sending notifications, replicating data across regions, or maintaining audit logs. Traditional approaches require complex polling mechanisms or tightly coupled systems that are difficult to maintain and scale.
Lambda's integration with DynamoDB Streams creates real-time, event-driven architectures that respond instantly to data changes. Every insert, update, or delete in your DynamoDB tables can trigger Lambda functions that propagate changes throughout your system, maintaining data consistency and enabling sophisticated workflows without complex coordination logic.
Common Problem Statements:
- How can we automatically update search indexes when database records change?
- What's the best way to maintain audit logs for all database modifications?
- How do we replicate critical data changes across multiple systems in real-time?
- Can we trigger automated workflows based on specific database events?
Solution Architecture:
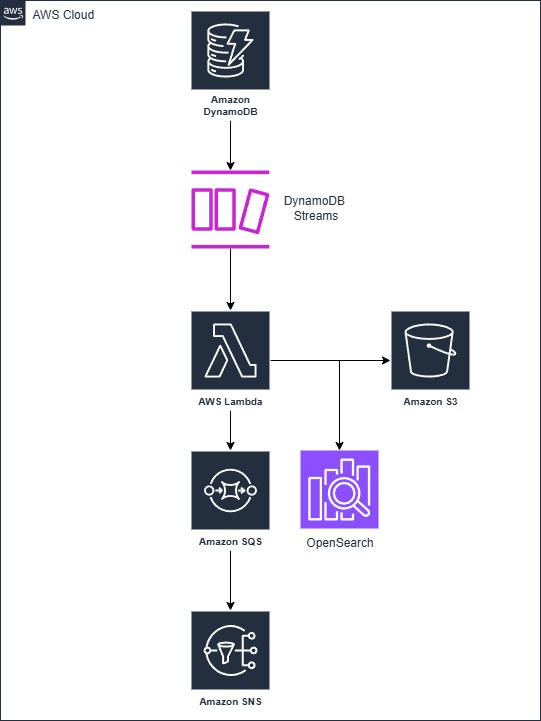
Enable DynamoDB Streams on your tables to capture all data modification events. Configure Lambda functions to process these streams, with different functions handling different types of changes or table updates. For audit logging, write change records to a separate DynamoDB table or S3 for long-term storage. For search index updates, integrate with Amazon OpenSearch or external search services. Implement error handling with exponential backoff and dead letter queues to ensure no events are lost, and use Lambda's built-in retry mechanisms for transient failures. Consider using EventBridge for complex routing scenarios where different downstream systems need different subsets of the change data.
Scheduled Tasks and Automation
Database Maintenance Application
Every database accumulates obsolete data over time, old user sessions, expired tokens, archived records, and temporary data that's no longer needed. Manual cleanup processes are often forgotten, leading to bloated databases, degraded performance, and increased storage costs. Traditional cron jobs require dedicated servers and complex scheduling infrastructure.
Lambda transforms database maintenance into a set-and-forget operation. Scheduled Lambda functions can automatically purge old data, optimize table performance, generate reports, and perform routine maintenance tasks without any server infrastructure. These functions run precisely when needed, scale to handle large datasets, and provide detailed logging for audit and troubleshooting purposes.
Common Problem Statements:
- How can we automatically remove expired data without impacting database performance?
- What's the most cost-effective way to run periodic database maintenance tasks?
- How do we ensure data retention policies are consistently enforced across all tables?
- Can we automate database optimization tasks to run during low-traffic periods?
Solution Architecture:
Use Amazon EventBridge to schedule Lambda functions with cron expressions for precise timing control. Configure the Lambda function to query DynamoDB for records older than your retention period, using pagination to handle large datasets without timing out. Implement batch deletion operations to optimize performance and minimize database load. Add CloudWatch logging to track deletion counts and processing times, set up SNS notifications for maintenance completion reports, and use DynamoDB's conditional writes to ensure data integrity during cleanup operations. For large-scale deletions, consider using DynamoDB's Time To Live (TTL) feature in combination with Lambda for more complex retention logic.
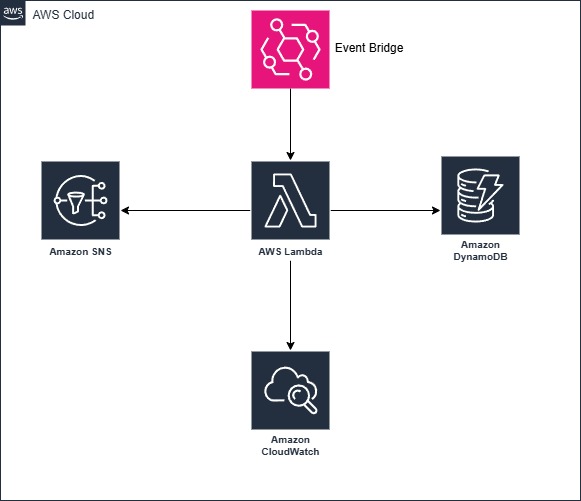
Scheduled Function Execution
Beyond database maintenance, organizations need to perform countless periodic tasks, generating reports, synchronizing data between systems, sending reminder emails, processing batch jobs, and monitoring system health. Traditional approaches require dedicated infrastructure that runs continuously, even when tasks execute only occasionally.
Lambda's integration with EventBridge creates a powerful scheduling platform that can trigger functions with precision timing, from every minute to once per year. These scheduled functions can orchestrate complex workflows, integrate with external systems, and handle both simple recurring tasks and sophisticated business processes without any always-on infrastructure.
Common Problem Statements:
- How can we automate report generation to run at specific times without maintaining servers?
- What's the best way to schedule data synchronization between multiple systems?
- How do we implement reliable backup processes that run during off-peak hours?
- Can we create automated monitoring that checks system health at regular intervals?
Solution Architecture:
Create EventBridge rules with cron or rate expressions to trigger Lambda functions on your desired schedule. For complex workflows, use Step Functions to orchestrate multiple Lambda functions in sequence or parallel. Store configuration data in Parameter Store or DynamoDB to make schedules and parameters easily adjustable without code changes. Implement comprehensive error handling with retry logic and failure notifications through SNS or Slack integrations. Use CloudWatch Events for monitoring execution success and duration, and consider using Lambda Destinations to handle success and failure scenarios differently. For time-sensitive operations, deploy functions across multiple regions to ensure availability even during regional outages.
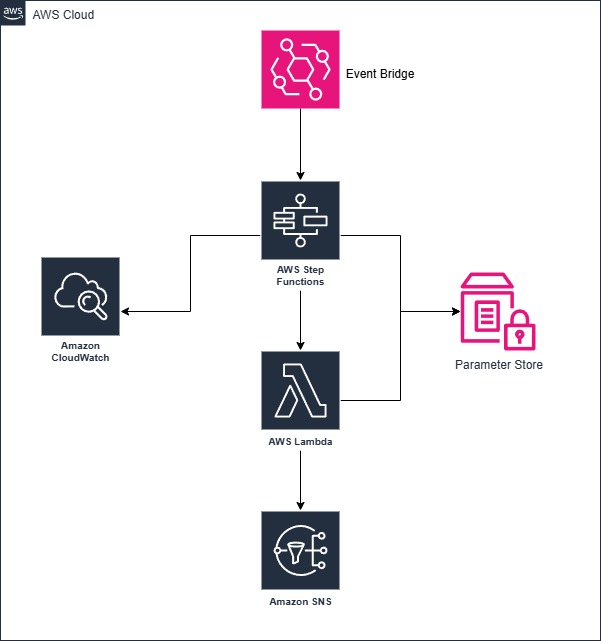
Best Practices and Considerations
Performance Optimization
Lambda performance optimization begins with understanding the execution environment and cold start behavior. Keep your deployment packages small by including only necessary dependencies, use Lambda Layers for shared code and libraries, and consider provisioned concurrency for latency-sensitive applications. Optimize memory allocation based on your function's CPU and I/O requirements, as Lambda allocates CPU power proportionally to memory. For database connections, implement connection pooling and reuse connections across invocations when possible.
Cost Management
Monitor your Lambda usage through CloudWatch metrics and AWS Cost Explorer to identify optimization opportunities. Use appropriate timeout values to prevent runaway functions from accumulating charges, and consider using Step Functions for long-running workflows instead of keeping Lambda functions active. Take advantage of the AWS Free Tier's generous Lambda allocation, and evaluate whether Reserved Capacity makes sense for predictable, high-volume workloads.
Security Considerations
Follow the principle of least privilege when configuring IAM roles for Lambda functions, granting only the minimum permissions required for each function's specific tasks. Use environment variables for configuration but never for sensitive data, instead, integrate with AWS Secrets Manager or Parameter Store for secure credential management. When functions need VPC access, carefully configure security groups and NACLs, and consider using VPC endpoints to avoid internet gateway routing for AWS service calls.
Monitoring and Observability
Implement comprehensive logging using CloudWatch Logs and consider structured logging formats for easier analysis. Use AWS X-Ray for distributed tracing to understand how your Lambda functions interact with other services and identify performance bottlenecks. Set up CloudWatch alarms for key metrics like error rates, duration, and throttling, and create dashboards that provide visibility into your serverless application's health and performance trends.
Conclusion
AWS Lambda represents a fundamental shift in how we build and deploy applications, moving from server-centric architectures to event-driven, automatically scaling systems that respond instantly to business needs. Whether you're processing files, integrating databases, automating maintenance tasks, or orchestrating complex workflows, Lambda provides the flexibility and power to build solutions that scale effortlessly from prototype to enterprise.
The serverless paradigm isn't just about reducing infrastructure overhead, it's about enabling innovation by removing the barriers between ideas and implementation. With Lambda, you can focus entirely on solving business logic while AWS handles all the underlying complexity of scaling, availability, and infrastructure management.
As organizations continue to embrace digital transformation, mastering serverless architectures becomes increasingly crucial for building resilient, cost-effective, and rapidly evolving systems. Lambda's extensive integration with the AWS ecosystem, combined with its pay-per-use pricing model, makes it an essential tool for any modern cloud strategy.
Stay tuned for our next post in the AWS Bytes series as we continue exploring the services that are reshaping how we build and deploy applications in the cloud.